

This article focuses on best practices for optimizing a Ruby on Rails web application for search engines (SEO). It's not meant to be a definitive or complete solution but only a group of base techniques that can be definitely extended, improved and mostly customized according to different needs.
RESTful Friendly URLs
Desing a good URL for SEO
The URLs of our web application have to be comprehensible by both human beings and search engines. The latter indeed, give an important weight to URLs to draw up the page rank. To understand well how to optimize them, let's take a look to how each URLs element influences this rank. Let's assume to have this example URL:
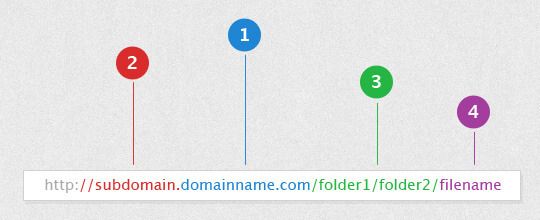
- domain name: it's the URL section that takes the greater account by search engines but it's not object of our optimization.
- subdomain: this part has a considerable weight too.
- folders: it's a good place where to put significant keywords.
- filename: it has less influence then folders but it's quite important to use keywords related to page content.
The above section helps us better understand that search engines decompose URLs, giving each section a different weight. In general, we can say that the less important keywords can be found at the end of the URL.
Improve Rails URLs
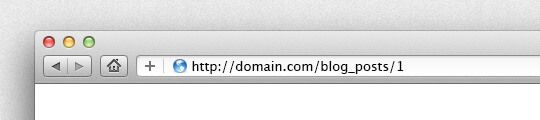
To create the URL, the default Rails behavior is to use the name of the resource we created followed by the id as a parameter. Let's take a look at how default URLs are generated by scaffolding a BlogPost resource:
rails generate scaffold BlogPost title:string slug:string
rake db:migrate
URLs will use blog posts id as a parameter:
In the controller, the scaffolded action will use the find method by default and the blog post id will be passed to it. Let's see what the show action does:
# GET /blog_posts/1
# GET /blog_posts/1.json
def show
@blog_post = BlogPost.find(params[:id])
respond_to do |format|
format.html
format.json { render json: @blog_post }
end
end
Our goal is to use a slug as a parameter of the URLs so they are both more valueable for search engines and more comprehensible by human begins. For example we want something like this:
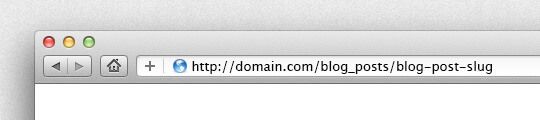
The first thing we have to do is change the find method with find_by_slug in every controller action that use this method (show, edit, delete). As usual, we'll look at the show method only:
# GET /blog_posts/slug
# GET /blog_posts/slug.json
def show
@blog_post = BlogPost.find_by_slug(params[:id])
respond_to do |format|
format.html
format.json { render json: @blog_post }
end
end
At last we have to overload the to_param method in the BlogPost model to force Rails to use the slug into the URLs instead of the id for this resource:
def to_param
slug
end
Note: if you don't want to edit methods in your controller you can always change the to_params as follow:
def to_param
"#{id}-#{slug}"
end
genrating URLs like this:
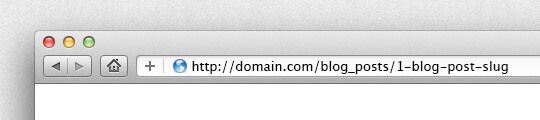
The find() method will automatically use the first part of the parameter only to perform the search.
Validated slugs
Now we have to add validations to be sure title and slug fields are always present and slug field is unique, because hereafter this will be equivalent to an id:
validates :title, presence: true
validates :slug, presence: true, uniqueness: true
We can still improve our code by automatically create the slug field parameterizing title before saving the blog post. Let's add this piece of code into the BlogPost model:
before_validation :create_slug
…
private
def create_slug
self.slug = name.try(:parameterize) if slug.blank?
end
Dynamic Meta Tags
Meta tags don't need a big introduction. They are tags invisible to users but quite useful for search engines to keep important information about our pages. The more they are related to content of the page the more they will be effective. So it's really important to have the ability to dynamically generate the meta tags of our web application, also because by doing so we avoid penalities for duplicate meta tags between website pages.
The following method shows how to generate dynamic meta tags using content we have already added without using specific database fields. The first thing we have to do is to render a new partial in our application layout (and in every other layout we want to add meta tags):
<head>
<!-- ... -->
<%= render 'shared/meta_tags' %>
<!-- ... -->
</head>
The partial shared/metatags.html.erb will contain the definition of meta tags we want to use. If meta tags will be present they will be used, otherwise a default value will be printed.
<title><%= yield(:title).presence || "Default title" %></title>
<meta name="keywords" content="<%= yield(:meta_keywords).presence || "default, keywords" %>" />
<meta name="description" content="<%= yield(:meta_description).presence || "Default description" %>" />
<meta name="author" content="<%= yield(:meta_author).presence || "Default Author" %>" />
Let's now create some methods inside the application_helper to easily pass custom meta tags to the layout:
# Meta tags helper methods
def meta_title(title)
content_for(:title, title)
end
def meta_description(description)
content_for(:meta_description, description)
end
def meta_keywords(keywords)
content_for(:meta_keywords, keywords)
end
def meta_author(author)
content_for(:meta_author, author)
end
We can now generate the dynamic meta tags for our blog posts into resource views, for example into blog_posts/show.html.erb:
<%
meta_title "#{@blog_post.title} - MyCoolBlog"
meta_keywords "#{@blog_post.categories.join(", ")}"
meta_description truncate(strip_tags(@blog_post.teaser), length: 200)
meta_author @blog_post.user
%>
I choose to pass meta tags from views (instead of from controller) beacause in this way we can use helper methods to customize them, as we have just done truncating and stripping HTML tags for the description meta tags.
Note: SEOmoz, one of the best SEO campigns managment software, began to reccomend to completely remove the keywords tag from our pages because, beside to not being taken into account by search engines, it also give to our competitors the ability to understand the list of our keywords, probably the result of years of work or considerable expense.
Canonical tag
Duplicate pages generate penalities. If we can't avoid to have two or more identical pages (for example using the root of a resource as root of our web application) we have to use the "canonical tag". This tag, added to the head section, informs search engines that the page has a duplicate and to consider another page when indexing.

For example, if (for some absurd reason) we have this 3 pages with same content but different URLs:
- /blog_posts/1
- /blog_posts/title
- /blog_posts/1-title
we have to insert into the head of last 2 pages the following link:
<head>
<link rel="canonical" href="/blog_posts/1" />
</head>
We can also use a technique similar to the above one. Let's add this code into main layout (or into the shared/meta_tags.html.erb partial previously created):
<%= yield :canonical %>
Now, into our application_helper let's add a method that creates the canonical link:
def canonical(url)
content_for(:canonical, tag(:link, rel: :canonical, href: url)) if url
end
At this point, into the views that generate duplicate contents we can add the following code:
<% canonical(blog_post_url(@blog_post)) %>
Sitemap & Rails
The XML Sitemap protocol was introduced by Google in 2005 and used soon by every other search engine. It's based on an XML file through which page information is provided. This helps search engines to get website structure and other valuable information like:
- index priority of each page
- page refresh rate
- last update date
To create a dynamic sitemap in a Rails application the best choice is to use a gem really simple to configure but highly customizable. "Sitemap" gem is perfect for our goal; let's add it to our Gemfile:
# ...
gem 'sitemap'
# ...
We can now procede installing the gem:
bundle install
rails generate sitemap:install
and editing the configuration file just created by the generator into config/sitemap.rb as follows:
Sitemap::Generator.instance.load host: "mywebsite.com" do
path :root, priority: 1
path :faq, priority: 0.5, change_frequency: "weekly"
resources :blog_posts
end
After running the rake task:
rake sitemap:generate
we will find our fresh sitemap into /public/sitemap.xml ready to be uploaded to Google Webmaster Tools.
301 redirect from old URLs
If we are building a new website (or upgrading an existing one) and we don't want to completely lose old URLs page rank, we can use a redirect with 301 status, not penalized from search engines because it corresponds to "Moved Permanently" HTTP status.
match "/old_path_to_blog_posts/:id", to: redirect("/blog_posts/%{id}s")
Other little (but big) advices
- HTML W3C validated and without inline javascript is good for search engines. If we can't avoid inline javascript it's better to place it at the end of the file (after the footer is a good place) beacause search engines may get tired of reading javascript and they can literally "jump" over your content.
- Alt tag on images helps for images search (like Google Images).

